Application Note IN Carta SINAPアプリケーションモジュールによる
ラベルフリー細胞セグメンテーション
- ラベルフリー細胞のロバストなセグメンテーションにSINAPディープラーニングアプリケーションモジュールを使用
- SINAPで事前に学習させたディープラーニングモデルを画像用にカスタマイズする簡単なワークフローを利用
- SINAPのラベルフリー細胞セグメンテーションで信頼性の高い定量データを得ます
PDF版(英語)
はじめに
Alla Zaltsman, PhD | Software Validation Scientist | モレキュラーデバイス
Misha Bashkurov, PhD | Product Owner | モレキュラーデバイス
Yu-Chen Hwang, PhD | Imaging Software Product Manager | モレキュラーデバイス
ラベルフリー細胞解析は、蛍光色素を使用するよりも優れた代替手段を提供します。なぜなら、科学者は、遺伝子組み換えや細胞を標識・固定するための試薬を使用することによる悪影響を受けることなく、生物学的プロセスを調べるという、ほぼ本来の条件下で生細胞を画像化することができるからです。透過光(TL)画像を使用して細胞を検出することも、特異性標識の蛍光チャンネルを最大限に利用するために効果的です。
対象オブジェクトを背景や残骸などから正確に区別する対物レンズのセグメンテーションは、画像解析ワークフローに必要なステップです。しかし、ラベルフリー顕微鏡のためのロバストな細胞セグメンテーション法は、細胞の透明な性質、撮影条件のばらつき、低コントラスト、陰影の問題のために、非常に困難な場合があります。
このアプリケーションノートでは、IN Carta™画像解析ソフトウェアの人工知能(AI)ベースのセグメンテーションツールであるSINAPを使用し、これらの困難なTLセグメンテーションの問題に取り組みます。
SINAPセグメンテーションワークフロー
SINAPはディープラーニングアルゴリズムを利用して、画像内の対象オブジェクトを検出。これは、対象オブジェクトと背景が手動で注釈された「グランドトゥルース」画像を使用したモデル学習によって行われます。
IN CartaのSINAPモジュールには、注釈付き画像が大規模なセットでトレーニングされた特異性の生物学的構造のベースモデルが含まれています。このベースモデルは、対物レンズのセグメンテーションに直接使用することができます(図1のA)。対物レンズを出発点として、そこからさらにアルゴリズムを "ティーチング "して、サンプル中の対象オブジェクトを除外し、目的の生物学的構造を認識することもできます(図1のB)。モデルの性能を向上させるためのこのようなアルゴリズムのさらなる学習は、ユーザー注釈付き画像を使用したユーザーフレンドリーなSINAPワークフロー内で行われます。学習プロセスは反復可能であり、モデルを改善するためにさらに多くの画像に注釈を付けることができます(図1、C)。
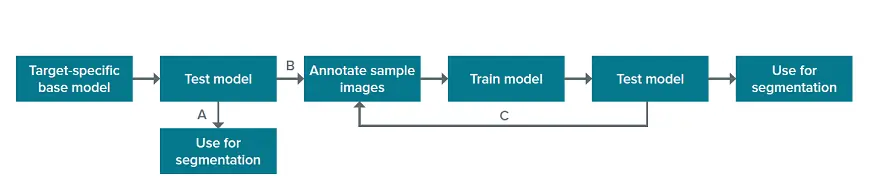
図1. SINAPセグメンテーションのワークフロー。
IN Cartaで提供されるベースモデルのリストには、透過光画像の細胞セグメンテーション用モデル(TL_Cellsモデル)が含まれています。
透過光セルベースモデルはラベルフリー細胞セグメンテーションに使用できます
TL_Cellsモデルは、画像特性(画像のコントラストや濃淡など)や細胞形態がトレーニングに使用した画像(図2)と類似している場合に、セグメンテーション(図1のA)に使用することができます。
図2の画像は背景にゴミが混じった凹凸があるが、このモデルは細胞の位置を特定し、背景から分離することに成功しました。
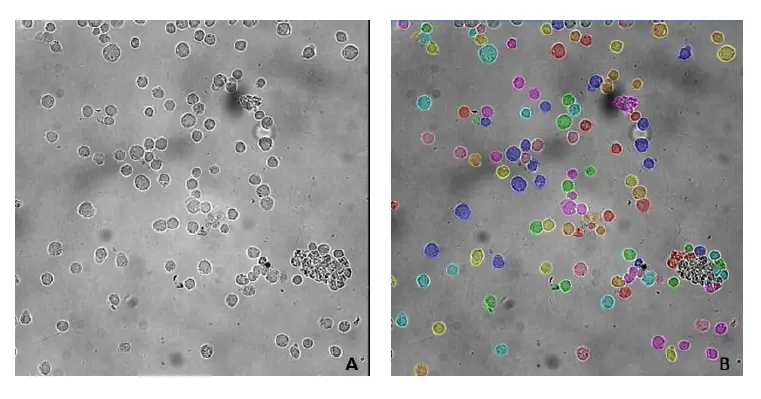
図2. TL_CellsベースモデルでセグメンテーションされたPBMC(末梢血単核細胞)。A) 元画像、B) TL_Cellsベースモデルによるセグメンテーション後のセルマスク。画像はIN Cell Analyzer 2200 (GE Healthcare)、対物レンズ40倍で取得。画像解析はIN Carta v1.15で行った。
透過光セルベースモデルは、画像内の細胞を正確にセグメンテーションするために、さらにトレーニングすることができます
テストサンプルの注釈付き画像を追加することで、ベースモデルをさらにトレーニングし、細胞をよりよく認識し、セグメンテーション結果を向上させることができます。
SINAPモジュールには使いやすいツールが含まれており、ユーザーは画像(または関心領域)に素早く注釈を付け、トレーニングセットに追加することができます。現在のモデルが失敗している、補正された特徴を封じ込めた画像でトレーニングセットを拡張することで、モデルを微調整してわずかな改善を図ることも、より深い学習プロセスのために再トレーニングすることもできます。
必要な画像補正の程度は、図3に示すようにサンプルによって異なります。
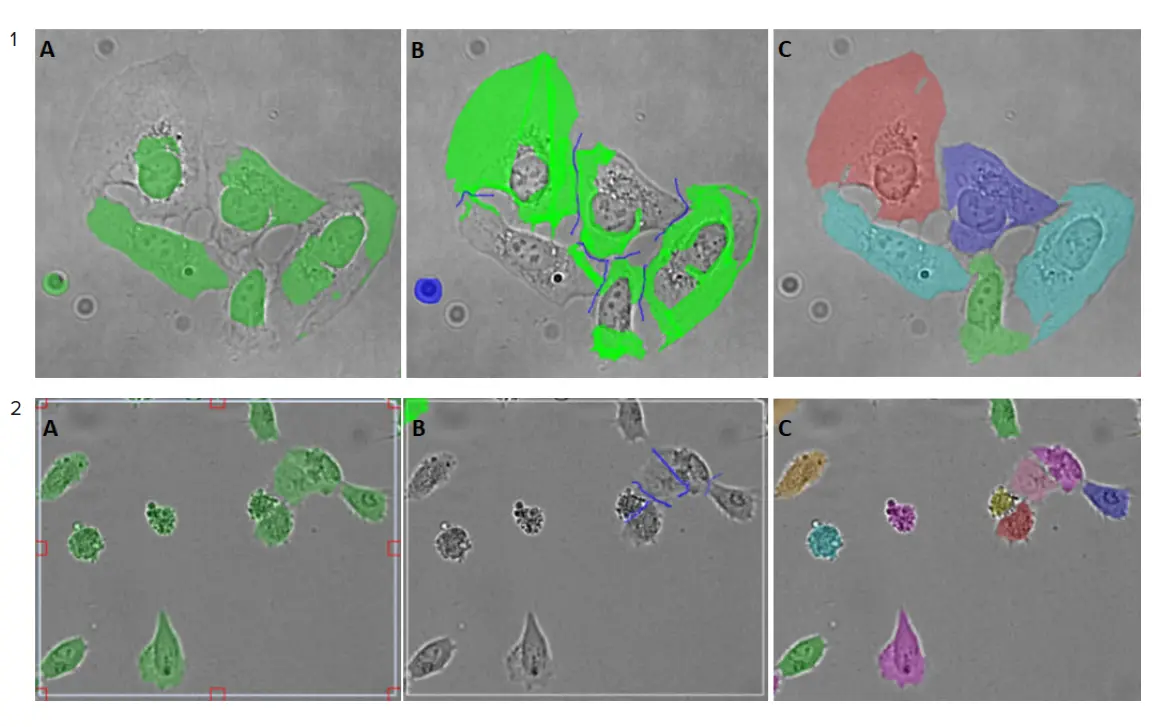
図3. 画像アノテーションプロセスの例。1) Hela細胞画像(ImageXpress® Micro Confocalハイコンテントイメージングシステムを使用、対物レンズ20倍で取得)、この例ではわずかな補正のみ必要。2) U2OS細胞の画像(IN Cell Analyzer 6000(GE Healthcare社製)を使用、対物レンズ20倍)。A-Cパネルはアノテーションプロセスのステップを表しています: A) セグメンテーションされた画像から、正しくセグメンテーションされた細胞と正しくセグメンテーションされなかった細胞を含む関心領域が選択されました。B) SINAPツールを用いて、細胞の輪郭を修正し(明るい緑)、背景を調整。更新された関心領域(B)がトレーニングセットに追加されました。C) トレーニングセットが収集されると、モデルがトレーニングされました。新たに学習されたモデルは画像セグメンテーションに適用。多色のセグメンテーションマスクにより、セグメンテーションはより正確になりました。
図 4 に示す例は、SINAP によるセグメンテーションのワークフ ローを示しています。図 4 のパネル A では、TL-Cells のベースモデルを用いて、図 1 の A で示した SINAP セグメンテーションのワークフローに従って CHO 細胞の画像をセグメンテーションしました。次に、手動で注釈を付けた関心領域(ROI)を用いてモデルを微調整。注釈付きROIには、正しくセグメンテーションされた細胞も、そうでない細胞も含まれていた。モデルをトレーニングするための注釈付きROIの数を5から10に増やすと、画像内の位置に関係なく、個々の細胞をピッキングするモデルの能力が向上しました(図4、パネルBとC、SINAPセグメンテーションワークフロー、図1、BとC)。

図4. SINAPモデルの微調整の例。IN CartaでTL_Cellsベースモデルを用いてセグメンテーションされたCHO細胞。1) 画像全体(視野)、2) 画像のアウトライン(黄色)領域。A) TL_Cellsベースモデルによるセグメンテーション。セグメンテーションマスク(多色)は、一部の細胞しか検出されていないことを示しています。B) 5つの注釈付きROIを使用して微調整したTL_Cellsモデルによるセグメンテーション。細胞の検出精度が大幅に向上しました。画像はImageXpress®Micro Confocalハイコンテントイメージングシステムを用い、対物レンズ10倍で取得しました。
SINAPでセグメンテーションされた標識不要細胞の数は、蛍光イメージングでセグメンテーションされた核の数と高い相関があります
SINAPによる細胞セグメンテーションの精度を評価するために、CHOおよびHEK 293細胞の連続希釈サンプルを用いました。核はHoechstでカウンター染色。透過光とDAPIチャンネル蛍光イメージングの両方を取得しました。透過光画像の細胞は微調整したTL_Cellsベースモデルを用いてセグメンテーションし、DAPI染色した核はNucleiロバストセグメンテーション法を用いてセグメンテーションしました。
その結果(図5)、細胞の数と核の数は、細胞密度の範囲にわたってよく相関しており、ペアのt検定分析では両者に有意差は認められませんでした。
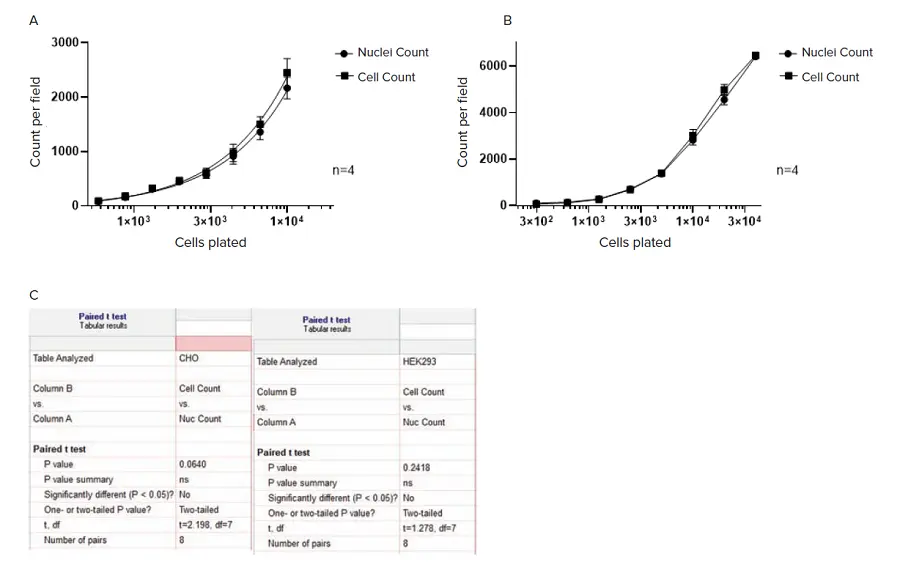
図5. SINAPでセグメンテーションされたラベルフリー細胞と、Nuclei Robustセグメンテーションで蛍光チャンネルにセグメンテーションされた核の計数。画像セグメンテーションと解析はIN Carta画像解析ソフトウェアv1.15を用いて行いました。A) CHO細胞;画像はImageXpress Microハイコンテントイメージングシステム、対物レンズ10倍で取得。B) HEK 293細胞;画像はSpectraMax® MiniMax™ 300イメージングサイトメーター、対物レンズ4倍で取得。すべてのデータは4ウェルの平均(±SD)。C) Paired t-test分析をGraphPad Prizmソフトウェアで行いました。
結論
- IN Carta SINAPディープラーニングモジュールは、ラベルフリー細胞のセグメンテーションに効果的に使用できます
- 透過光での細胞セグメンテーションのために事前に訓練されたベースモデルは、追加注釈画像による微調整や再学習によって簡単にカスタマイズできます
- ラベルフリー細胞セグメンテーションの精度は、透過光における核のセグメンテーションに匹敵します
SINAPを使用した場合の蛍光チャネルにおける核のセグメンテーションに匹敵します
IN Carta 画像解析ソフトウェアについて詳しくはこちら>>
PDF版(英語)